- Audio kills the video star (Jan 29, 2006)
- Batch-as-batch-can! (27.1.2006)
- Beware of unknown enumerators (26.1.2006)
- It's official: Microsoft's compiler is twice as good as the HP-UX compiler! (24.1.2006)
- Getting organized (21.1.2006)
- Should Lisp programmers be slapped in public? (17.1.2006)
- How to crash your compiler with a one-liner, in two easy lessons (16.1.2006)
- Address of the union (11 Jan 2006)
- A syntax error in a comment, or: The case of the vanishing parenthesis (10 Jan 2006)
- To cut a long filename short, I lost my mind (8.1.2006)
- Doppelgänger modules, or The Curse of EightPlusThree (7.1.2006)
- What's my email address? (4 Jan 2006)
- Reimschrift (1.1.2006)
- Blog entries for December 2005
Audio kills the video star (Jan 29, 2006)
Movie podcasts are the next big thing after blogging and podcasting. For the time being, I'll stick to my blog, thanks very much for asking, but I do listen to a lot of podcasts while commuting or exercising. Occasionally, I also watch some of the Channel 9 videos where Microsoft engineers and employees talk about their work. No matter what you think about the company in general, everybody knows that Microsoft hires smart people, so there is a lot to learn from them. Many of those videos contain demos or at least feature casually-dressed geeks scribbling frantically on whiteboards, which, of course, is a must-see (ahem). But quite a few videos could be enjoyed almost just as well in pure audio format. Unfortunately, most of the Channel 9 content is in video format (*.wmv) only, which will neither fit nor play on my 512 MB MP3 player. I'm pretty much a newbie in all things video, and so I was glad that Minh Truong suggested a way to convert WMV to WMA using Windows Media Encoder. This actually works fine, but it's a lot of settings to remember (see the screenshots below), and it produces WMA instead of MP3 or OGG format which I'd prefer.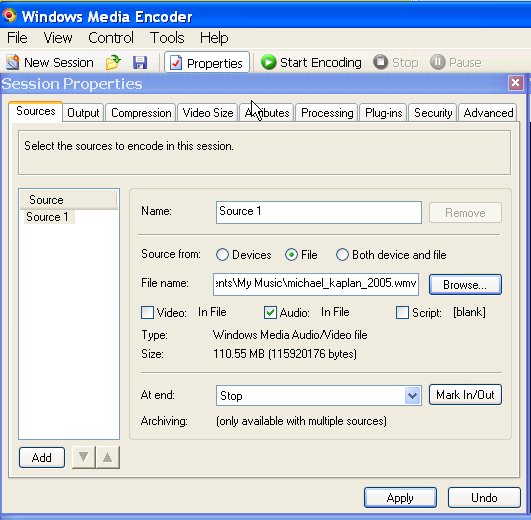
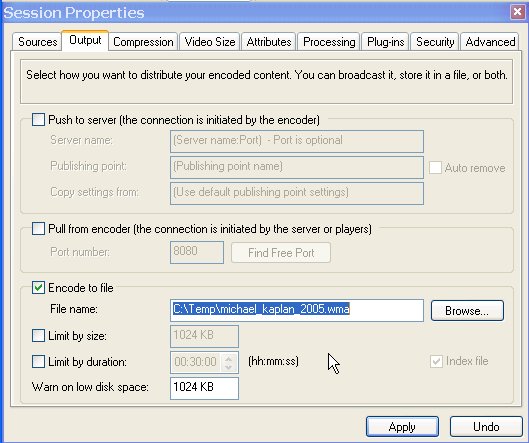
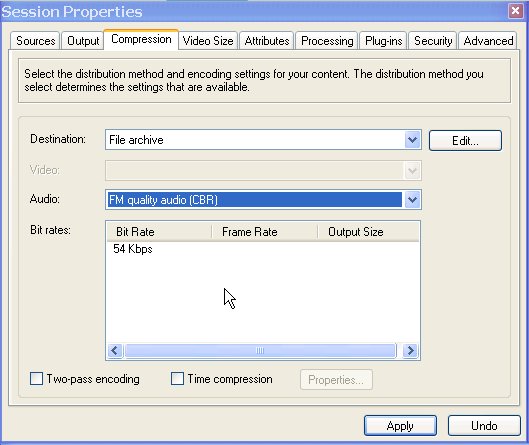 Fortunately, I found that Windows Media Encoder actually ships with a script called
WMCmd.vbs
which takes a gazillion parameters and automates the conversion process!
And indeed, the following trivial command line produces a WMA audio file
from a WMV video:
Fortunately, I found that Windows Media Encoder actually ships with a script called
WMCmd.vbs
which takes a gazillion parameters and automates the conversion process!
And indeed, the following trivial command line produces a WMA audio file
from a WMV video:
cd c:\Program Files\Windows Media Components\Encoder cscript.exe WMCmd.vbs -input c:\temp\foo.wmv -output c:\temp\foo.wma -audioonlyThere are a number of options to control the quality and encoding of the output which I haven't explored at all. So now I only need to find a reasonable WMA-to-MP3 converter which can be used from the command line. batchenc and dBpowerAMP Music Converter look like they could help with that part of the job, but I'm not sure. Sounds like I have a plan for next weekend

Batch-as-batch-can! (27.1.2006)
So here I confess, not without a certain sense of pride: Sometimes I boldly go where few programmers like to go - and then I write a few lines in DOS batch language. Most of the time, it's not as bad as many people think. Its bad reputation mostly stems from the days of DOS and Windows 95, but since the advent of Windows NT, the command processor has learnt quite a few new tricks. While its syntax remains absurd enough to drive some programmers out of their profession, you can now actually accomplish most typical scripting tasks with it. In particular, the for statement is quite powerful. Anyway - a while ago, one of my batchfiles started to act up. The error message was "The system cannot find the batch label specified - copyfile". The batch file in question had a structure like this:@echo off rem copy all pdb files in the current directory into a backup directory set pdbdir=c:\temp\pdbfiles for /r %%c in (*.pdb) do call :copyfile "%%c" %pdbdir% if errorlevel 1 echo Error occurred while copying pdb files echo All pdb files copied. goto :eof rem copyfile subroutine :copyfile echo Copying %1 to %2... copy /Y %1 %2 >nul goto :eofI know what you're thinking - no, this is not the problem. This is how you write subroutines in DOS batch files. Seriously. And yes, the above script can of course be replaced by a single
copy command. The original script couldn't;
it performed a few extra checks for each and every file to be copied in
the :copyfile subroutine, but it also contained a lot of extra fluff which
distracts from the actual problem, so what you're seeing here is a stripped-down
version.
The error message complained that the label copyfile could not be found. Funny,
because the label is of course there. (The leading colon identifies it as a label.)
And in fact, the very same subroutine could be called just fine from elsewhere in
the same batch file!
For debugging, I removed the @echo off statement so that the command processor
would log all commands it executes; this usually helps to find most batch file
problems. But not this one - removing the echo "fixed" the bug. I added the
statement again - now I got the error again. Removed the echo statement - all is
fine.
Oh great. It's a Heisenbug.
So I added the echo statement back in again and stared at the script hoping to find the
problem by the old-fashioned method of "flash of inspiration".
No inspiration in sight, though. Not knowing what to do, I added a few empty
lines between the for and the if errorlevel statement and ran the script
again - no error message! Many attempts later, I concluded that it's
the sheer length of the script file which made the difference between
smooth sailing and desperation. By the way, the above demo script works
just fine, of course, because I stripped it down for publication.
Google confirmed my suspicion: Apparently, there are cases where
labels cannot be found even though they are most certainly in the batch file.
Maybe the length of the label names matters -
Microsoft Knowledge Base Article 63071
suggests that only the first eight characters of the label are significant.
However, copyfile has exactly eight characters!
I still haven't solved this puzzle. If you're a seasoned batch file
programmer sent to this place by Google and can shed some light on this,
I could finally trust that script again...
-- ClausBrod - 27 Jan 2006
"How bad is the Windows command line really?"
-- ClausBrod - 01 Apr 2016
Thanks a lot, Reinder!
-- ClausBrod - 05 Apr 2015
From http://help.wugnet.com/windows/system-find-batch-label-ftopict615555.html, I tentatively conclude that
you need two preconditions for this to hit you:
- the batch file must not use CRLF line endings
- the label you jump to must span a block boundary
Beware of unknown enumerators (26.1.2006)
The other day, I was testing COM clients which accessed a collection class via a COM-style enumerator (IEnumVARIANT). And those clients crashed
as soon as they tried to do anything with the enumerator. Of course, the
same code had worked just fine all the time before. What changed?
In COM, a collection interface often implements a function called GetEnumerator()
which returns the actual enumerator interface (IEnumVARIANT), or rather,
a pointer to the interface. In my case, the signature of that function was:
HRESULT GetEnumerator(IUnknown **);Didn't I say that
GetEnumerator is supposed to return an IEnumVARIANT
pointer? Yup, but for reasons which I may cover here in one
of my next bonus lives, that signature was changed from IEnumVARIANT to IUnknown.
This, however, is merely a syntactic change - the function actually still
returned IEnumVARIANT pointers, so this alone didn't explain the crashes.
Well, I had been bitten before by smart pointers,
and it happened again this time! The COM client code declared a smart
pointer for the enumerator like this:
CComPtr<IEnumVARIANT> enumerator = array->GetEnumerator();This is perfectly correct code as far as I can tell, but it causes a fatal avalanche:
- The compiler notices that
GetEnumeratorreturns anIUnknownpointer. This doesn't match the constructor of this particular smart pointer which expects an argument of typeIEnumVARIANT *. - So the compiler looks for other matching constructors.
- It doesn't find a matching constructor in
CComPtritself, butCComPtris derived fromCComPtrBasewhich has an undocumented constructorCComPtrBase(int). - To match this constructor, the compiler converts the
return value of
GetEnumerator()into aboolvalue which compresses the 32 or 64 bits of the pointer into a single bit! (Ha! WinZip, can you beat that?) - The boolean value is then passed to the
CComPtrBase(int)constructor. - To add insult to injury, this constructor doesn't even use its argument and instead resets the internally held interface pointer to 0.
GetEnumerator declaration was bogus.
But neither C++ nor ATL really helped to spot this issue.
On the contrary, the C++ type system (and its implicit
type conversions) and the design of the ATL smart pointer classes
collaborated to hide the issue away from me until it was too late.
It's official: Microsoft's compiler is twice as good as the HP-UX compiler! (24.1.2006)
A few days ago, I dissed good ol'aCC on the HP-UX platform,
but for political correctness, here's an amusing quirk in Microsoft's compiler as well.
Consider the following code:
typedef struct foobar gazonk; struct gazonk;The C++ compiler which ships with VS.NET 2003 is quite impressed with those two lines:
fatal error C1001: INTERNAL COMPILER ERROR (compiler file 'msc1.cpp', line 2701) Please choose the Technical Support command on the Visual C++ Help menu, or open the Technical Support help file for more informationWhat the compiler really wants to tell me is that it does not want me to redefine
gazonk. The C++ compiler in VS 2005 gets this right.
If you refer back to the previous blog entry, you'll find
that it took me only one line to crash aCC on HP-UX. It took two lines in the above
example to crash Microsoft's compiler. Hence, I conclude that their compiler
is only half as bad as the HP-UX compiler.
If you want to argue with my reasoning, let me tell you that out there in the wild,
I have rarely seen a platform-vs-platform discussion based on
facts which were any better than that. Ahem...
Getting organized (21.1.2006)
I've been meaning to install and tame Minimo on my PDA for some time. Finally, I can tap my way through my first blog posting from this cute little browser. I had to switch off the SSR (Small Screen Rendering) feature, but now, at last, my PocketPC displays web pages in a manner that is suitable for human consumption. I never understood why IE, after quite a number of releases of the Windows Mobile/CE platform, still sucks that badly as a browser. Typing with the stylus is a pain in the youknowwhere, so I probably won't be blogging from my PDA that often But still, I love the Minimo browser, even though it is in its
early infancy. It seems to do a much better job at displaying most web sites than IE;
it groks the CSS-based layout of my own web site; it makes use of the VGA screen on
my PDA; and I can now even use TWiki's direct editing facilities from my organizer.
This project really makes me wonder what it would take to start developing for the PocketPC platform...
|
|
Should Lisp programmers be slapped in public? (17.1.2006)
After fixing a nasty bug today, I let off some steam by surfing the 'net for fun stuff and new developments. For instance, Bjarne Stroustrup recently reported on the plans for C++0x. I like most of the stuff he presents, but still was left disturbingly unimpressed with it. Maybe it's just a sign of age, but somehow I am not really thrilled anymore by a programming language standard scheduled for 2008 which, for the first time in the history of the language, includes something as basic as a hashtable. Yes, I know that pretty much all the major STL implementations already have hashtable equivalents, so it's not a real issue in practice. And yes, there are other very interesting concepts in the standard which make a lot of sense. Still - I used to be a C++ bigot, but I feel the zeal is wearing off; is that love affair over? Confused and bewildered, I surf some other direction, but only to have Sriram Krishnan explain to me that Lisp is sin. Oh great. I happen to like Lisp a lot - do I really deserve another slap in the face on the same day? But Sriram doesn't really flame us Lisp geeks; quite to the contrary. He is a programmer at Microsoft and obviously strongly impressed by Lisp as a language. His blog entry illustrates how Lisp influenced recent developments in C# - and looks at reasons why Lisp isn't as successful as many people think it should be. Meanwhile, back in the C++ jungle: Those concepts are actually quite clever, and solve an important problem in using C++ templates. In a way, C++ templates use what elsewhere is called duck typing. Why do I say this? Because the types passed to a template are checked implicitly by the template implementation rather than its declaration. If the template implementation says f = 0 andf is a template
parameter, then the template assumes that f provides an assignment
operator - otherwise the code simply won't compile. (The difference
to duck typing in its original sense is that we're talking about
compile-time checks here, not dynamic function call resolution at run-time.)
Hence, templates do not require types to derive from certain classes or
interfaces, which is particularly important when using templates for primitive
types (such as int or float). However, when the type check fails,
you'll drown in error messages which are cryptic enough to violate
the Geneva convention. To fix the error, the user of a template often
has to inspect the implementation of the template to understand
what's going on. Not exactly what they call encapsulation.
Generics in .NET improve on this by specifying constraints explicitly:
static void Foobar<T>(IFun<T> fun) where T : IFunny<T>
{
... function definition ...
}
T is required to implement IFunny. If it doesn't, the compiler will
tell you that T ain't funny at all, and that's that. No need to dig
into the implementation details of the generic function.
C++ concepts extend this idea: You can specify pretty arbitrary restrictions
on the type. An example from Stroustrup's and Dos Reis' paper:
concept Assignable<typename T, typename U=T> {
Var<T> a;
Var<const U> b;
a = b;
};
;; using this in a template definition:
template <typename T, typename U>
where Assignable<T, U>
... template definition ...
So if T and U fit into the Assignable concept, the compiler will
accept them as parameters of the template. This is cute: In true C++
tradition, this provides maximum flexibility and performance,
but solves the original problem.
Still, that C# code is much easier on the eye...
How to crash your compiler with a one-liner, in two easy lessons (16.1.2006)
Just to prove that I'm not a Windows-only guy, here's an amusing HP-UX interlude. The following code resulted from frantic coding activity in a semi-functional terminal window:static int static int;Compiling this nonsense via
aCC foo.cpp leads to amusing results:
$aCC foo.cpp
( 0) 0x00269b54 toolError__12ErrorHandlerF11StringTokenRC8Positione + 0x58 [
/opt/aCC/lbin/ctcom.pa20]
( 1) 0x0025d164 __assertprint__FPCcT1i + 0x40 [/opt/aCC/lbin/ctcom.pa20]
( 2) 0x002a5b08 id__4NodeCFv + 0x30 [/opt/aCC/lbin/ctcom.pa20]
( 3) 0x0017dd88 doReduction1__FiR12ScannerValueP12ScannerValue + 0x3240 [/op
t/aCC/lbin/ctcom.pa20]
( 4) 0x0018281c yyparse__Fv + 0xc44 [/opt/aCC/lbin/ctcom.pa20]
( 5) 0x002271d4 DoCompile__8CompilerFv + 0x228 [/opt/aCC/lbin/ctcom.pa20]
( 6) 0x000aadac DoCompile__8CompilerFP6Buffer + 0x34 [/opt/aCC/lbin/ctcom.pa
20]
( 7) 0x000b067c DoCompileFile__8CompilerFPc + 0x25c [/opt/aCC/lbin/ctcom.pa2
0]
( 8) 0x00230ec4 main + 0x694 [/opt/aCC/lbin/ctcom.pa20]
( 9) 0xc0143478 _start + 0xc0 [/usr/lib/libc.2]
(10) 0x00155ce4 $START$ + 0x1a4 [/opt/aCC/lbin/ctcom.pa20]
Error (internal problem) 200: "foo.cpp", line 1 # Assertion failed at [File
"Node.C"; Line 558].
static int static int;
^^^^^^^^^^^^^^^^^^^^^
The other one-liner which I remember also used to kill the C++ compiler
on HP-UX:
char *p = (char *)0x80000000;With current versions of
aCC, this works as expected, so I cannot present
a stacktrace here, but I do remember that we debugged into the issue and
found that, for unknown reasons, the compiler tried to dereference the pointer
address, and then crashed miserably...
Address of the union (11 Jan 2006)
The following C++ code will be rejected by both Visual C++ and gcc:
class BOX {
public:
BOX() {}
};
union {
void *pointers[8];
BOX box;
};
gcc says something like "error: member `BOX box member with
a default constructor! Now I'm sure that all those CEOs around the world who
are currently sacking people in the thousands would readily agree that union
members aren't constructive enough, but why even turn this into a C++ language rule?
I have a workaround for this now, but I'm still a little puzzled about the compiler
restriction. My guess is that the compiler is trying to avoid intialization
ambiguity in a scenario like this:
class FOO {
int foo;
public:
FOO() : foo(42) {}
};
class BAR {
int bar;
public:
BAR() : bar(4711) {}
};
union {
FOO foo;
BAR bar;
};
Which constructor "wins" here? But then, C++ isn't exactly over-protective in other
areas, either, so if I want to shoot myself into the foot, get out of my way, please.
Or is there another reason? Hints most welcome.
A syntax error in a comment, or: The case of the vanishing parenthesis (10 Jan 2006)
The other day, Visual C++ would not compile this code, reporting lots and lots of errors:
if (!strncmp(text, "FOO", 3))
{
foobar(text); //üüü
}
else
{
gazonk();
}
Now this was funny because that code had not changed in ages, and so far had compiled
just fine. At first, I couldn't explain what was going on. Hmmmm... note the
funny u-umlauts in the comment. Why would someone use a comment like that?
Well, the above code was inherited from source code originally written on an HP-UX
system. For long years, the default character encoding on HP-UX systems has been
Roman8. In that encoding, the
above comment looked like this:
foobar(text); //■■■
(If your browser cannot interpret the Unicode codepoint U+25A0, it represents a
filled box.)
So the original programmer used this special character for graphically highlighting the
line. In Roman8, the filled box has a character code of 0xFC. On a Windows system
in the US or Europe, which defaults to displaying characters according to ISO8859-1 (aka Latin1), 0xFC will
be interpreted as the German u-umlaut ü.
So far, so good, but why the compilation errors?
On the affected system, I ran the code through the C preprocessor (cpp), and ended
up with this preprocessed version:
if (!strncmp(text, "FOO", 3))
{
foobar(text);
else
{
gazonk();
}
Wow - the preprocessor threw away the comment, as expected, but also the closing
parenthesis } on the next line! Hence, the parentheses in the code are now
unbalanced, which the compiler complains bitterly about.
But why would the preprocessor misbehave so badly on this system? Shortly before,
I had installed the Windows multi-language UI pack
(MUI) to run tests in Japanese; because of that, the system defaulted to a Japanese
locale. In the default Japanese locale, Windows assumes that all strings are
encoding according to the Shift-JIS
standard, which is a multi-byte character set (MBCS).
Shift-JIS tries to tackle the problem of representing the several thousands of
Japanese characters. The code positions 0-127 are identical with US ASCII.
In the range from 128-255, some byte values indicate "first byte of a
two-byte sequence" - and 0xFC is indeed one of those indicator bytes.
So the preprocessor reads the line until it finds the // comment indicators.
The preprocessor changes into "comment mode" and reads all characters until
the end of the line, only to discard them. (The compiler doesn't care about
the comments, so why bother it with them?)
Now the preprocessor finds the first 0xFC character, and - according to
the active Japanese locale - assumes that it is
the first byte of a two-byte character. Hence, it reads the next byte (also 0xFC,
the second "box"), converts the sequence 0xFC 0xFC into a
Japanese Kanji character, and throws that character away.
Then the next byte is read, which again is 0xFC
(the third "box" in the comment), and so the preprocessor will slurp
another byte, interpreting it as the second byte of a two-byte character.
But the next byte in the file after the third "box" is a 0x0A, i.e. the
line-feed character which indicates the end of the line. The preprocessor
reads that byte, forms a two-byte character from it and its predecessor (0xFC),
discards the character - and misses the end of the line.
The preprocessor doesn't have a choice now but to continue searching for the next LF,
which it finds in the next line, but only after the closing parenthesis. Which is
why that closing parenthesis never makes it to the compiler. Hocus, pocus, leavenotracus.
So special characters in comments are not a particularly brilliant idea; not just because
they might be misinterpreted (in our case, displayed as ü instead of
the originally intended box), but because they can actually cause the compiler to
fail.
If you think this could only happen in a Roman8 context, consider this variation
of the original code:
if (!strncmp(text, "MENU", 4))
{
display_ui(text); //Menü
}
else
{
gazonk();
}
Here, we're simply using the German translation for menu in the comment;
we're not even trying to be "graphical" and draw boxes in our comments.
But even this is enough to cause the same compilation issue as with my original example.
Now, in my particular case, the affected code isn't likely to be compiled in Japan or China
anytime soon, except in that non-standard situation when I performed my experiments with
the MUI pack and a Japanese UI. But what if your next open-source
project attracts hundreds of volunteers around the world who want to refine the code, and
some of those volunteers happen to be from Japan? If you're trying to be too clever
(or too patriotic) in your comments, they might have to spend more time on finding
out why the code won't compile than on adding new features to your code.
To cut a long filename short, I lost my mind (8.1.2006)
Yesterday, I explained how easy it is to inadvertedly load the same executable twice into the same process address space - you simply run it using its short DOS-ish filename (likeSample~1.exe)
instead of its original long filename (such as SampleApplication.exe).
For details, please consult the original blog entry.
I mentioned that one fine day I might report how exactly this happened
to us, i.e. why in the world our app was started using its short filename.
Seems like today is such a fine day  Said application registered itself as a COM server, and it does so using
the services of the ATL Registrar.
Upon calling
Said application registered itself as a COM server, and it does so using
the services of the ATL Registrar.
Upon calling RegisterServer, the registrar will kindly create all the required
registry entries for a COM server, including the LocalServer entry which
contains the path and filename of the server. Internally, this will call the
following code in atlbase.h:
inline HRESULT WINAPI CComModule::UpdateRegistryFromResourceS(UINT nResID,
BOOL bRegister, struct _ATL_REGMAP_ENTRY* pMapEntries)
{
USES_CONVERSION;
ATL::CRegObject ro;
TCHAR szModule[_MAX_PATH];
GetModuleFileName(_pModule->GetModuleInstance(), szModule, _MAX_PATH);
// Convert to short path to work around bug in NT4's CreateProcess
TCHAR szModuleShort[_MAX_PATH];
GetShortPathName(szModule, szModuleShort, _MAX_PATH);
LPOLESTR pszModule = T2OLE(szModuleShort);
...
Aha! So ATL deliberately converts the module name (something like SampleApplication.exe)
into its short-name equivalent (Sample~1.exe) to work around an issue in the
CreateProcess implementation of Windows NT.
MSKB:179690
describes this problem: CreateProcess could not always handle blanks in pathnames
correctly, and so the ATL designers had to convert the path into its short-path
version which converts everything into an 8+3 filename and hence guarantees that
the filename contains no blanks.
Adding insult to injury, MSKB:201318
shows that this NT-specific bug fix in ATL has a bug itself... and, of course, our problem is,
in fact, caused by yet another bug in the bug fix (see earlier blog entry).
For my application, the first workaround was to use a modified version of atlbase.h which checks the
OS version; if it is Windows 2000 or later, no short-path conversion
takes place. Under Windows NT, however, we're caught in a pickle: Either we
use the original ATL version of the registration code and thus map the executable
twice into the address space, or we apply the same fix as for Windows 2000,
and will suffer from the bug in CreateProcess if the application is installed
in a path which has blanks in the pathname.
In my case, this was not a showstopper issue because the application is targeting Windows 2000 and XP
only, so I simply left it at that.
Another approach is to use the AddReplacement
and ClearReplacements APIs of the ATL registrar to set our own conversion rules
for the module name and thereby override ATL's own rules for the module name:
#include <atlbase.h>
#include <statreg.h>
void RegisterServer(wchar_t *widePath, bool reg)
{
ATL::CRegObject ro;
ro.AddReplacement(L"Module", widePath);
reg ? ro.ResourceRegister(widePath, IDR_REGISTRY, L"REGISTRY") :
ro.ResourceUnregister(widePath, IDR_REGISTRY, L"REGISTRY");
}
Doppelgänger modules, or The Curse of EightPlusThree (7.1.2006)
Windows, even in its latest incarnations, still exhibits quite a bit of quirky behavior which is due to its DOS roots, or at least due to the attempt to remain compatible with code which was created for DOS. Most of the time, I am not even surprised anymore when I come across 16-bit limitations or similar reminiscences of the past. But sometimes, I only become aware of them when my code crashes. This happened some time ago with an application I am working on. When I started the app in a certain way, it would simply crash very early during startup. It took a while to break this down into the following trivial code example which consists of a main executable and a DLL which is loaded into the executable via LoadLibrary, i.e. dynamically. Here is the code for the main executable,SampleApp.cpp:
#include <stdio.h>
#include <conio.h>
#include <windows.h>
#include <psapi.h>
static void EnumModules(const char *msg)
{
printf("\n==========================================================\n");
printf("List of modules in the current process %s:\n", msg);
HMODULE hMods[1024];
DWORD cbNeeded;
HANDLE hProcess = GetCurrentProcess();
// inquire modules loaded into process
if( EnumProcessModules(hProcess, hMods, sizeof(hMods), &cbNeeded)) {
// print name and handle for each module
for ( unsigned int i = 0; i < (cbNeeded/sizeof(HMODULE)); i++ ) {
char szModName[MAX_PATH];
if ( GetModuleFileNameEx( hProcess, hMods[i], szModName, sizeof(szModName))) {
printf(" %s (0x%08X)\n", szModName, hMods[i] );
}
}
}
CloseHandle( hProcess );
}
extern "C" __declspec(dllexport) int functionInExe(void)
{
printf("Now in functionInExe()\n");
return 42;
}
int main(void)
{
EnumModules("before loading DLL");
HMODULE hmod = LoadLibrary("SampleDLL.dll");
EnumModules("after loading DLL");
printf("\nPress key to exit.\n");
_getch();
return 0;
}
This code loads a DLL called SampleDLL.dll. Before and after loading
the DLL, it enumerates the modules which are currently loaded into the process;
this is only to demonstrate the effect which led to the crash in the other app I
was working on.
SampleDLL.dll is built from this code (SampleDLL.cpp):
extern "C" __declspec(dllimport) int functionInExe(void);
extern "C" __declspec(dllexport) void gazonk(void)
{
int i = functionInExe();
}
The main executable exports a function called functionInExe, and the DLL
calls this function, and so it has an explicit reference to the main executable
which the linker needs to resolve. This is an important piece of the puzzle.
And here is a simple makefile which shows how to build the two modules:
all: SampleApplication.exe SampleDLL.dll clean: del *.obj *.exe *.dll SampleApplication.exe: SampleApp.obj link /debug /out:SampleApplication.exe SampleApp.obj psapi.lib SampleApp.obj: SampleApp.cpp cl /Zi /c SampleApp.cpp SampleDLL.dll: SampleDLL.obj link /debug /dll /out:SampleDLL.dll SampleDLL.obj SampleApplication.lib SampleDLL.obj: SampleDLL.cpp cl /Zi /c SampleDLL.cppLet's assume that the above files (
SampleApp.cpp, SampleDLL.cpp and makefile)
are all in a directory c:\temp\dupemod, and that we built the code by
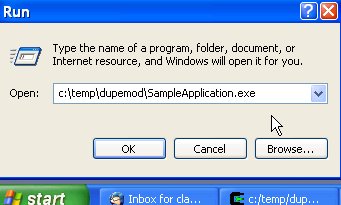
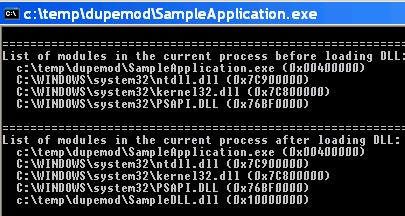
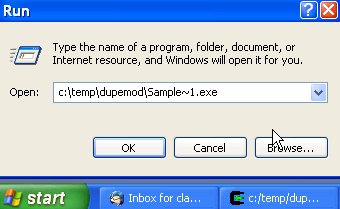
running nmake in that directory. Now let's run the code as shown in
the screenshots below.
| Long filename | Short filename |
|---|---|
|
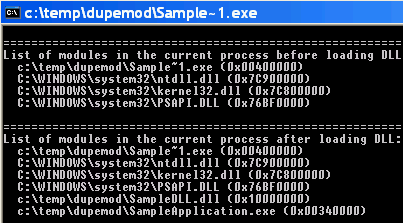
|
c:\temp\dupemod\Sample~1.exe and
c:\temp\dupemod\SampleApplication.exe into its address space.
Both refer, of course, to the same file, which means that we have loaded
the executable twice!
This happens only if we run the executable using its 8+3 DOS name, i.e. Sample~1.exe.
When run with a long filename, everything works as expected. So when we load
SampleDLL.dll, the OS loader tries to resolve the references which this
DLL makes to other modules. One of those modules is SampleApplication.exe.
The OS loader should be able to map this reference to the instance of the
executable which is already mapped into the address space. However, it seems
that the OS loader cannot figure out that Sample~1.exe and SampleApplication.exe are
actually the same file, and therefore loads another instance of the executable!
BTW, this happens both on Windows 2000 and Windows XP systems.
In this trivial example, the only damage done is probably just that the main
executable consumes twice the virtual address space. In
a large application, the consequences can be more severe, and in our case
they were.
Microsoft also documents some effects of this issue in Knowledge Base articles,
for example KB218475
and KB193513.
The only workarounds I see are:
- Rename the executable to that it uses a name which fits into the 8+3 format.
- Make sure that nobody ever runs the executable using its short name.
What's my email address? (4 Jan 2006)
On various occasions, I had already tried to make sense out of directory services such as LDAP and Microsoft's ADSI. Now, while that stuff is probably not rocket science, the awkward terminology and syntax in this area have always managed to shy me away; most of the time, there was another way to accomplish the same without going through LDAP or ADSI, and so I went with that. This time, the task was to retrieve the email address (in SMTP format) for a given user. In my first attempt, I tried to tap the Outlook object model, but then figured that a) there are a few systems in the local domain which do not have Outlook installed and b) accessing Outlook's address info causes Outlook to display warnings to the user reporting that somebody apparently is spelunking around in data which they shouldn't be accessing. Which is probably a good idea, given the overwhelming "success" of Outlook worms in the past, but not exactly helpful in my case. However, everybody here is connected to a Windows domain server and therefore has access to its AD services, so that sounded like a more reliable approach. I googled high and low, dissected funky scripts I found out there and put bits of pieces of them together again to form this VBscript code:
user="Claus Brod"
context=GetObject("LDAP://rootDSE").Get("defaultNamingContext")
ou="OU=Users,"
Set objUser = GetObject("LDAP://CN=" & user & "," & ou & context)
WScript.Echo(objUser.mail)
groups=objUser.Get("memberOf")
For Each group in groups
WScript.Echo(" member of " & group)
Next
This works, but the OU part of the LDAP string (the "ADsPath") depends on the local
organizational structure and needs to be adapted for each particular environment;
I haven't found a good way to generalize this away. Hints most welcome.
PS: For those of you on a similar mission, Richard Mueller provides some helpful
scripts at http://www.rlmueller.net/freecode3.htm.
Reimschrift (1.1.2006)
Mark Rosenfelder erfindet in "If English was written like Chinese" glatt mal eine neue Schrift für das Englische: Das römische Alphabet wird kurzerhand ersetzt durch Yingzi, hypothetische englische Entsprechungen der chinesischen hanzi. Das beschreibt Rosenfelder so umwerfend gut, daß man hinterher wirklich zu verstehen glaubt, wie das chinesische Schriftsystem funktioniert. Naja, so ungefähr jedenfalls. Vor allem aber lernt man, daß die chinesische Schrift mit einer ganz eigenen Denkart einhergeht. Es ist schon eine Weile her, daß mich ein Artikel über Sprache so fasziniert hat.Blog entries for December 2005
to top
Edit | Attach image or document | Printable version | Raw text | Refresh | More topic actions
Revisions: | r1.15 | > | r1.14 | > | r1.13 | Total page history | Backlinks
Revisions: | r1.15 | > | r1.14 | > | r1.13 | Total page history | Backlinks
Blog.DefinePrivatePublic200601 moved from Blog.BlogOnSoftware200601 on 29 Jan 2007 - 18:58 by ClausBrod - put it back
 Blog
Blog